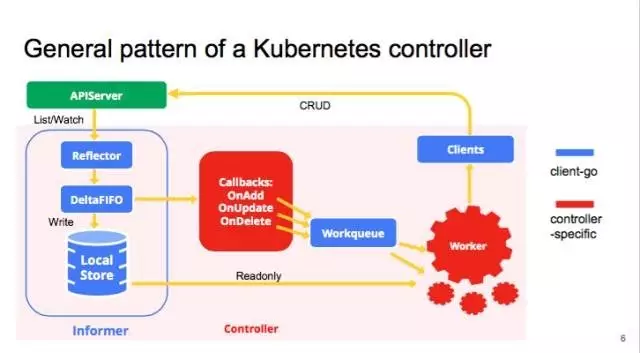
kubernetes之Gang scheduling
此篇为《Gang scheduling in Kubernetes》文档翻译,个人翻译。
动机
Kubernetes目前已经成为主流的容器平台编排方案,在服务与存储层面已经取得成功性的大规模应用了,并且原生k8s支持Spark。同时社区也在致力于将ML机器学习框架运行在k8s之上,比如kubeflow/tf-operator,在整合kube-arbitrator期间,我们发现以下需求合并到default-scheduling是更好的措施。
定义
Gang Scheduling:任务实例要么全部或全部不执行。如果没有足够的资源来调度所有的pod,那么改任务包含的pod一个都不被调度,即All-or-none模式。如果任务中有任何的pod运行失败或未被调度,那么所有的pod必须能够优雅的终止退出
使用场景
- 以
pod group的方式调度pod,all-or-nothing模式(TensorFlow,MPI)
最初的需求来自于TesnsorFlow(以及MPI):运行Tensorflow/MPI任务,一个任务重的所有task单元必须保证能够一起启动,否则不启动其中任何一个task。如果资源充足到满足运行所有的task那么一切运行正常,但是在绝大部分情况下,尤其是在不具备任何保障的环境下,这种理想环境是不存在的。最坏的场景是由于”资源死锁”导致所有的任务都处于pending状态:每个任务只启动了部分task,该任务还在等他其他的task启动运行。此种问题在联邦域或者跨域场景下会变的更加糟糕,具体细节可详见 - 以
pod group的方式调度pod,最小满足模式(Spark)
与Tensorflow/MPI不同的是,Spark不需要所有的task(driver/executors)都启动:driver是必要的,但是对于excutors来说是多多益善的(但是至少得有一个)。在此场景下,必须要求scheduler能够保障“最小可用资源”(gang-scheduling),另外其他task还是能够以默认调度策略进行调度。 - 同一个
pod group中支持不同pod模板(Tensorflow/Spark/PMI)。对于Tensorflow/Spark任务,tasks的镜像可能会不同。例如in tensorflow job,master和worker就使用不同的镜像。spark下的场景也类似,driver和executor也可能不尽相同。这种情况下就要求k8s在gang-scheduling调度模式中能够在同一pod group中根据不同的pod模板做出相应调度。
PS:目前来说,Spark on Kubernetes首先启动运行driver,然后driver再启动其对应的executors,相关的讨论细节请详见
4. pod group支持pod顺序/优先级启动(Spark)
由于#2(min availiable != desire),#3(不同的tasks),tasks必须按序启动。拿Spark举例,minAvailable=2,desire=4(其中包括driver)。如果没有足够的资源去运行所有的4个tasks,scheduler能够确保driver以及其对应的一个executor能够启动运行,而不是两个exectors(minAvaiable=2)
5. 对其他特性具备可扩展性,e.g. IndexedJob(MPI)gang-scheduling能够满足不少工作场景,但是对于某些场景来说还不够完善,比如MPI。这就要求
gang-scheduling对于一些特性的场景具备可扩展性。
开放问/答
gang-scheduling只支持batch工作需求?
答案是不,尽管大多数batch工作需求是需要这样的特性,但是对于scheduler来说,gang-scheduling是一种“捆绑式,all-or-nothing模式”,scheduler并不清楚pod中运行的是啥。gang-scheduler必须具备其他特性以支持除batch工作需求的其他场景。gang-scheduling如何支持其他框架,比如Flink,Storm?[k82cn]:我更倾向在资源规划阶段利用好资源可规划的这个阶段来达到scheduler对这些框架的支持,资源规划其实是一个必不可少的共性阶段,在此之后提供给用户可配置能力来自定义使用。e.g.(一种可自定义的
tensorflow控制器)1.gang-scheduling:任务中的pods将不会启动,除非有足够的资源满足2.job group:框架(e.g. TensorFlow,Spark)需要一组jobs共同工作才能保证正常运行,比如Spark中的driver和worker,TensorFlow中的master和workers目标
- 定义管理或者调度批量工作场景的方式.比如
ML - 在默认调度器中支持
gang-schedulingNon-Goal
- 通过
Application API Object原生支持job group功能设计
默认调度器是在Pod级别进行调度。当声明了新的Kind,为了对scheduler无任何变化,就必须将scheduler从controller-manager解耦出来。对于批量任务处理,支持Pods(比如Job vs Tasks)之间的关系的特性又是必要的,e.g. gang-shceduler。如下的设计就是满足管理具备关联关系的pods,并且gang-schedluing能够工作其上。如下示例规范的定义的新的Kind:QueueJob就保证了能够管理pods之间关系。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59type QueueJob struct {
metav1.TypeMeta
metav1.ObjectMeta
// cron job 的行为定义包括 minAvailable.
Spec QueueJobSpec
// 当前QueueJob状态
Status QueueJobStatus
}
// QueueJobSpec 描述 job 执行情况以及何时真正运行
type QueueJobSpec struct {
// 定义 QueueJob 的优先级。
//"system-node-critical" 和 "system-cluster-critical"是最高的优先级。
// 其他任何命名则必须创建一个用于此名称的PriorityClass 对象
//如果未定义,那么QueueJob的优先级将是默认值,如果未提供默认值的话将会是0。
// +optional
PriorityClassName string
// 优先级属性值。许多时候系统组件通过此属性来发现QueueJob的优先级。
// 开启优先级准入接入特性之后,它将阻止用户配置此属性,准入控制器将使用PriorityClassName来配置此属性。
// 参数值越大优先级越高
// +optional
Priority *int32
// 期望副本数
Replicas int32
// 可运行状态最少Pod数, 默认为nil.
MinAvailable *int32
// Pods控制器,如下合法属性值:
// k8s;
// customized
Controller string
// pod描述模板
Template PodTemplateSpec
}
// QueueJobStatus represents the current state of a QueueJob.
type QueueJobStatus struct {
// The number of actively running pods.
// +optional
Running int32
// The number of pods which reached phase Succeeded.
// +optional
Succeeded int32
// The number of pods which reached phase Failed.
// +optional
Failed int32
// The minimal available pods to run for this QueueJob
// +optional
MinAvailable int32
}
开放讨论:
Scheduler
默认调度器也会对QueueJob进行监控,根据OwnerReference和selector在调度器的pending缓存中“填入”Pods。由于QueueJob中的pods是被批量调度的,存入pending queue的是QueueJob而不是其中的pods。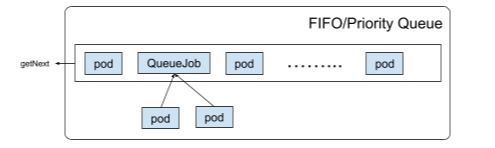
开放讨论:
- 一种选择是使用不同的
queue去存放不同的QueueJob,scheduler则必须根据资源使用情况进行速率处理- 另一种选择是在
multi-scheduler feature中构建一个单独的库来实现此特性。
在scheduler loop中,getNext将获取下一个对象进行调度。scheduleOne和scheduleBatch分别作为调度Pod和QueueJob的使用依据。
scheduleOne
从FIFO/PriQueue中获取pod之后,scheduler将调用scheduleOne方法调度该pod。当选择主机节点时触发抢占式多任务处理,scheduler将尝试避免给QueueJob中的pod进行优先处理,类似于PDB(PodDisruptionBudget)。若pod被驱逐,QueueJob的控制器将管理器生命周期,比如kill掉整个的QueueJob(for MPI),或者重新创建那些被kill掉的pods以便再次调度(for Spark)。
scheduleBatch
如果一个QueueJob从FIFO/PriQueue中获取,其中的pdos将执行scheduleBatch进行批量处理,辅助方法将对QueueJob进行调度。scheduleBatch也拥有三个主要阶段:
选取主机节点,#TODO「assume」,绑定。
选取主机节点
在此阶段,scheduler将为批量任务中的pods选择匹配QueueJob中.spec.minAvailable属性要求的节点。Running和Pending状态的pods数量都被统计作为.spec.minAvailable的考量。
pods总数 <.spec.minAvailable
根据ResourceQuota,QueueJobController也许不会创建足够的(.spec.minAvailable)pods。该QueueJob会被记录在backlog中直到足够的pods被创建。运行状态的
pods<.spec.minAvailable
如果QueueJob内没有足够的running状态的pods(包括#TODO「assumed」但没有启动的),scheduler将尝试批量调度.spec.minAvailable-Running pods数量的pods:
a. 调用调度算法来为每个pod获取distHost,如果获取distHost失败,scheduler将会尝试选择一个pod进行抢占式调度,#TODO the pod eviction will be triggered in batch until all pods got distHost or preemption candidate
b. 如果所有的pods都获取到distHost,将继续批量的将这些pods绑定。
c. 否则,遗忘它们。Running pods>.spec.minAvailable
如果QueueJob已经有足够的running pods,那些pending状态的pods将会一个个的被调度。如果支持QueueJob抢占式调度的话则会调用scheduleOne方法。
总之,当调度pod失败,pods的状况将会被更新.QueueJob对应的控制器也将会管理QueueJob的生命周期。
抢占式调度
gang-scheduling支持QueueJob级别的抢占式调度。在选取主机节点的阶段,如果无法将pod调度到主机节点上,那么scheduler将会尝试选取某个pod进行抢占式调度。schedule将不会触发驱逐直到所有的pod获得disHost或者具备优先抢占的“权利”。如果抢占式候选者不为空,则会批量的对pod进行驱逐,同时#TODO「en-queue the QueueJob」。
在下个scheduling loop时,QueueJob将会被调度。
* 如果驱逐失败了,当再次调度QueueJob时,scheduler将会再次触发对pod的驱逐。
* scheduler不会绑定QueueJob的pods除非所有的pods已经终止退出了,同时原本那些被pod抢占的资源将会被释放,以供待调度的QueueJob使用。只有优先级较高的pod才能够使用空闲资源,并且触发QueueJob抢占式调度。
资源“饥饿”vs空闲
由于QueueJob是批量的关联多个pods,达到QueueJob对资源需求“满意”是常见的场景需求,常见的两种如下:
- 保持资源空闲除非搞优先级的
QueueJbo获得足够的资源 - “回填”对于以及满足它们资源的那些低优先级/同等优先级的
QueueJob
假想
在选取主机节点阶段,scheduler将假设pod已经获取到distHost或者成为优先候选者。如若发生错误异常,将忽略pods包括那些QueueJob中已经被消费调度的。pods的状态也会得到及时的更新。
绑定
过了“消费”pods阶段,pods已经具备被绑定的前提。pod将会被一个个的被绑定。如果其中任何一个失败了,scheduler会及时更新pod状态,会取消之后涉及到的pod的绑定不包括已经完成绑定了的。剩下的工作就是QueueJob Controller去管理它们的生命周期了,比如 对于MPI任务来说,就是kill掉整个的QueueJob,而对于Spark任务来说仅仅是重新创建那些失败的worker pod。
Controller
QueueJobController
如若.spec.Controller声明为k8s,那么QueueJobController将会按如下管理QueueJob的生命周期:Pod/QueueJob创建QueueJobController会创建pods达到.spec.minAvailable的数量,并等待kube-scheduler批量的将这些pods进行调度。
#TODO
#待继续更新